Appearance
Awesome Video Diffusion 
A curated list of recent diffusion models for video generation, editing, restoration, understanding, nerf, etc.


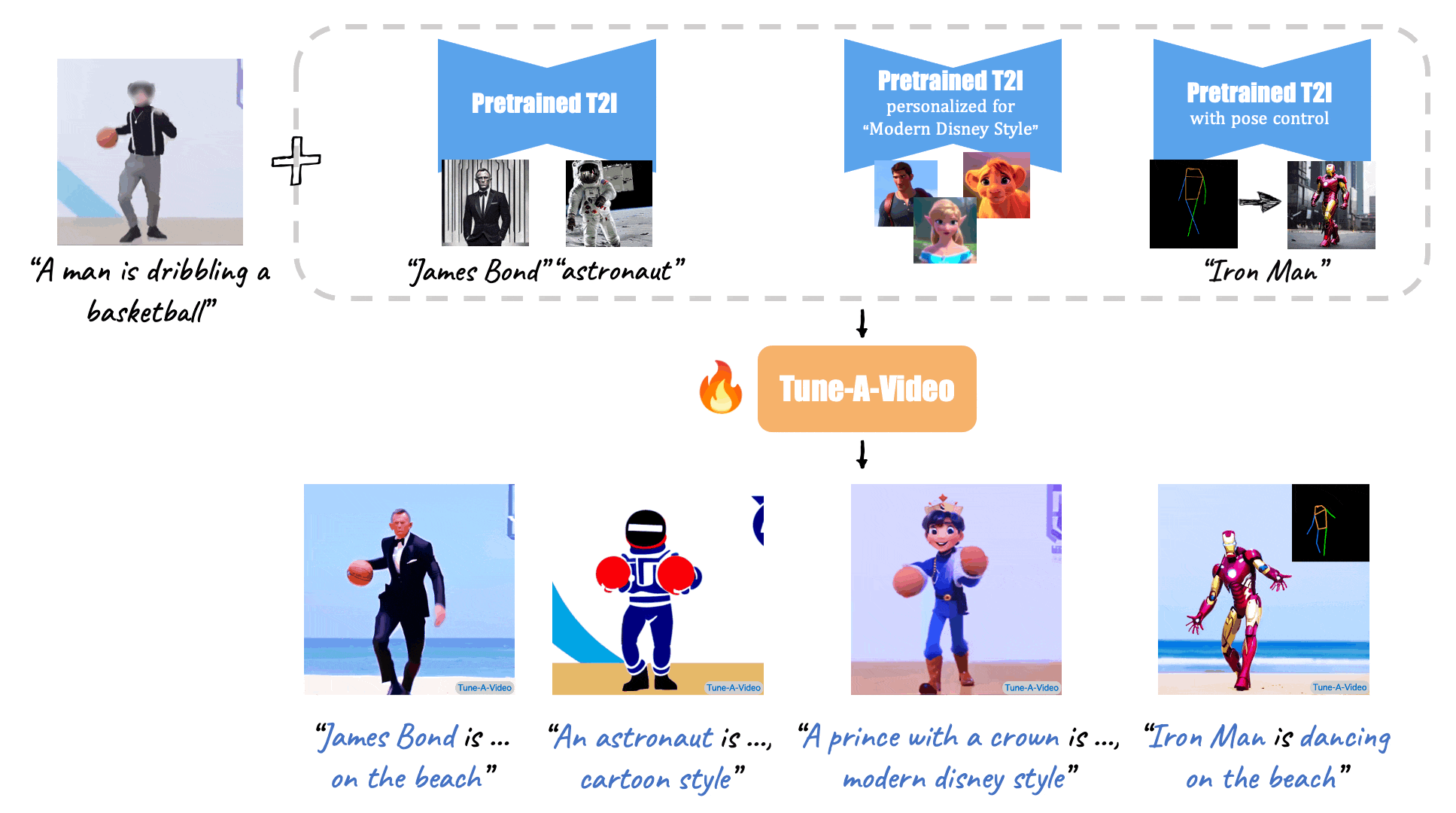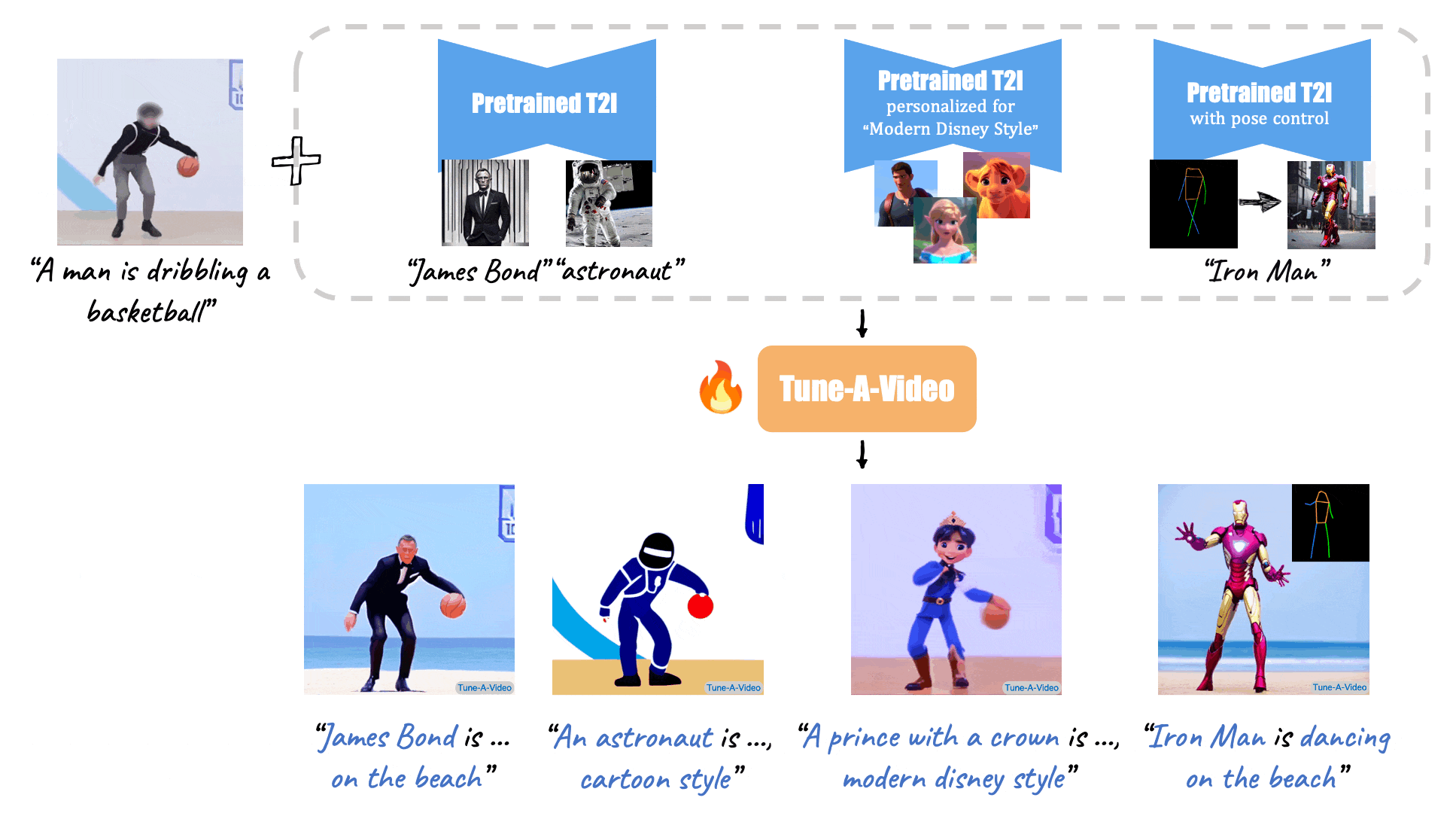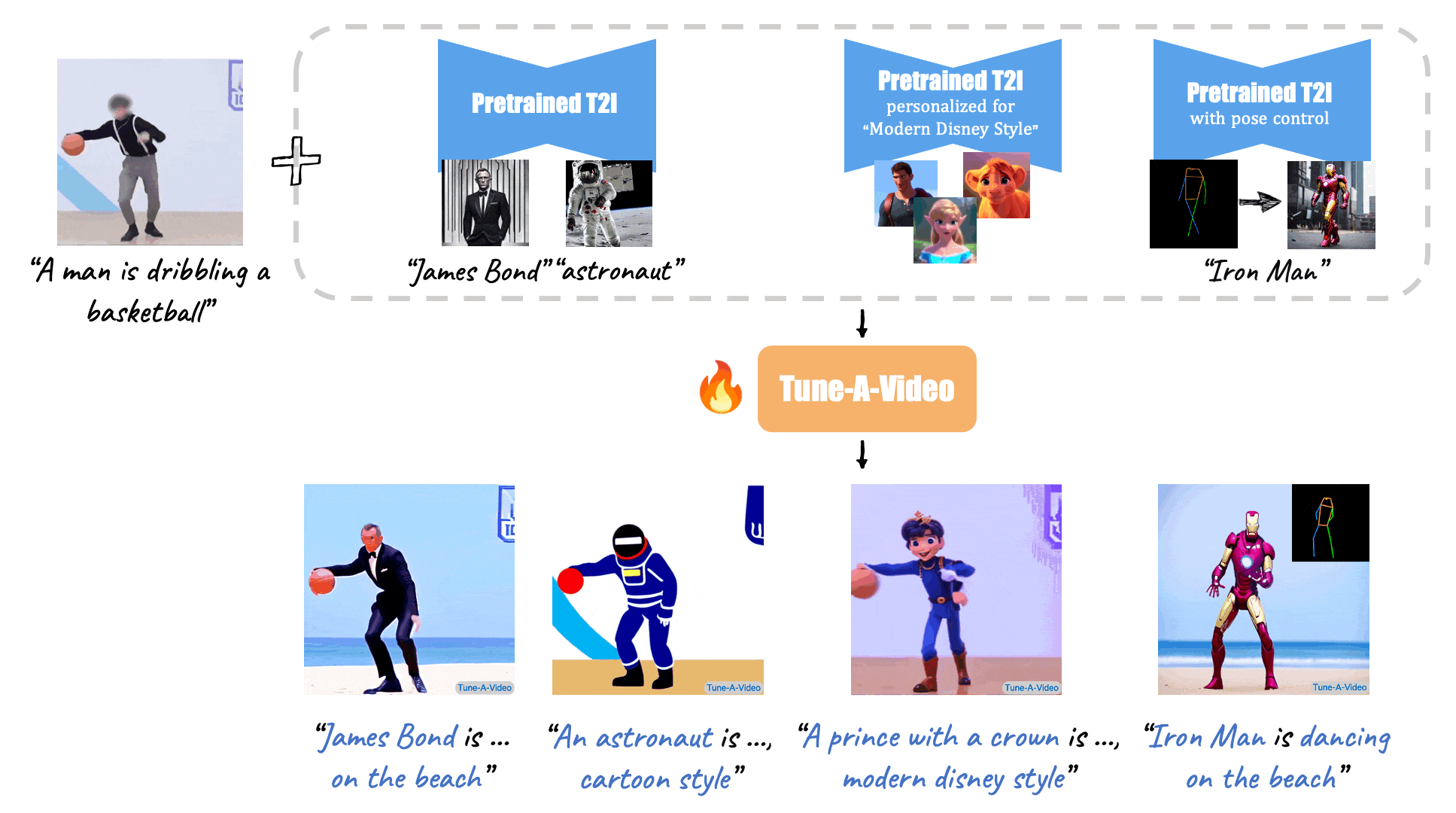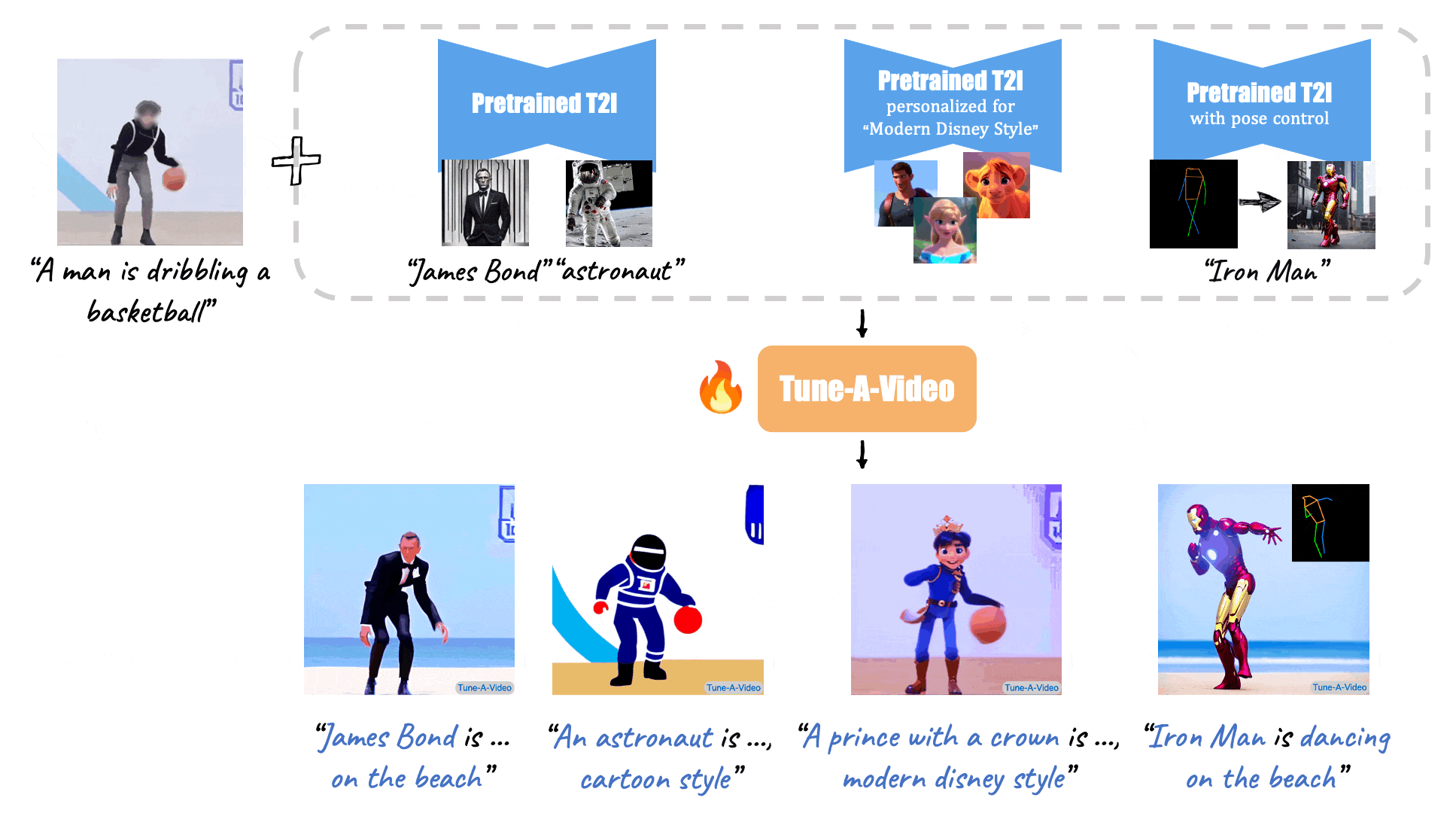


(Source: Make-A-Video, Tune-A-Video, and Fate/Zero.)
Table of Contents
- Open-source Toolboxes and Foundation Models
- Evaluation Benchmarks and Metrics
- Commercial Product
- Video Generation
- Efficient Video Generation
- Controllable Video Generation
- Character Customization
- Motion Customization
- Long Video / Film Generation
- Video Generation with 3D/Physical Prior
- Video Editing
- Human or Subject Motion
- Video Enhancement and Restoration
- Audio Synthesis for Video
- Talking Head Generation
- Reinforcement Learning for Video Generation
- Policy Learning
- Virtual Try-On
- 3D
- 4D
- Game Generation
- AI Safety
- Rendering with Virtual Engine
- Open-World Model
- Video Understanding
- Healthcare and Biology
- Other Applications
- Code-rendered Video Generation
Open-source Toolboxes and Foundation Models
NanoI2V

A step-by-step teaching series for building an Image-to-Video model from scratch in PyTorch, covering 3D VAEs, DiT, Flow Matching, RoPE, and conditioning.FastVideo: A unified inference and post-training framework for accelerated video generation

Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model


HunyuanVideo: A Systematic Framework For Large Video Generative Models

Pyramidal Flow Matching for Efficient Video Generative Modeling

VideoCrafter: A Toolkit for Text-to-Video Generation and Editing


















Evaluation Benchmarks and Metrics
LikePhys: Evaluating Intuitive Physics Understanding in Video Diffusion Models via Likelihood Preference (Oct., 2025)
Stable Cinemetrics: Structured Taxonomy and Evaluation for Professional Video Generation (Sep., 2025)
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation (Mar., 2025)

VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness (Mar., 2025)

Impossible Videos (Mar., 2025)

MEt3R: Measuring Multi-View Consistency in Generated Images (Jan., 2025)

Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation (Dec., 2024)

Evaluation Agent, Efficient and Promptable Evaluation Framework for Visual Generative Models (Dec., 2024)

Frechet Video Motion Distance: A Metric for Evaluating Motion Consistency in Videos (Jun., 2024)

T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation (Jun., 2024)

ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation (NeurIPS, 2024)

PEEKABOO: Interactive Video Generation via Masked-Diffusion (CVPR, 2024)

T2VScore: Towards A Better Metric for Text-to-Video Generation (Jan., 2024)

StoryBench: A Multifaceted Benchmark for Continuous Story Visualization (NeurIPS, 2023)

VBench: Comprehensive Benchmark Suite for Video Generative Models (Nov., 2023)
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation (Nov., 2023)

EvalCrafter: Benchmarking and Evaluating Large Video Generation Models (Oct., 2023)

Evaluation of Text-to-Video Generation Models: A Dynamics Perspective (Jul., 2024)

VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models (May., 2024)

Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (CVPR, 2024)

ReLight My NeRF: A Dataset for Novel View Synthesis and Relighting of Real World Objects (CVPR, 2023)

Commercial Product
Video Generation
Helios: Real Real-Time Long Video Generation Model (Mar., 2026)

MOVA: Towards Scalable and Synchronized Video-Audio Generation (Feb., 2026)

VINO: A Unified Visual Generator with Interleaved OmniModal Context (Jan., 2026)

UltraViCo: Breaking Extrapolation Limits in Video Diffusion Transformers (Oct., 2025)

VISTA: A Test-Time Self-Improving Video Generation Agent (Oct., 2025 | CVPR 2026)
UniVideo: Unified Understanding, Generation, and Editing for Videos (Oct., 2025)

PUSA V1.0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation (July., 2025)

LayerFlow : A Unified Model for Layer-aware Video Generation (May., 2025)

InfLVG: Reinforce Inference-Time Consistent Long Video Generation with GRPO (May., 2025)

Training-Free Efficient Video Generation via Dynamic Token Carving (May., 2025)
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis (Apr., 2025)
MAGI-1: Autoregressive Video Generation at Scale (Apr., 2025)

SphereDiff: Tuning-free Omnidirectional Panoramic Image and Video Generation via Spherical Latent Representation (Apr., 2025)

Packing Input Frame Context in Next-Frame Prediction Models for Video Generation (Apr., 2025)

SkyReels-V2: Infinite-length Film Generative Model (Apr., 2025)

Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model (Apr., 2025)
Aligning Text-to-Video Generation Models with Prompt Optimization (Mar., 2025)

Target-Aware Video Diffusion Models (Mar., 2025)

MagicComp: Training-free Dual-Phase Refinement for Compositional Video Generation (Mar., 2025)

Video-T1: Test-Time Scaling for Video Generation (Mar., 2025)

Temporal Regularization Makes Your Video Generator Stronger (Mar., 2025)
VACE: All-in-One Video Creation and Editing (Mar., 2025)

RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers (Feb., 2025)
DLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation (Feb., 2025)
Magic 1-For-1: Generating One Minute Video Clips within One Minute (Feb., 2025)

Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT (Feb., 2025)

Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search (Jan., 2025)

RepVideo: Rethinking Cross-Layer Representation for Video Generation (Jan., 2025)

Large Motion Video Autoencoding with Cross-modal Video VAE (Dec., 2024)
MotiF: Making Text Count in Image Animation with Motion Focal Loss (Dec., 2024)
VideoDPO: Omni-Preference Alignment for Video Diffusion Generation (Dec., 2024)
Autoregressive Video Generation without Vector Quantization (Dec., 2024)

AniDoc: Animation Creation Made Easier (Dec., 2024)

Video Diffusion Transformers are In-Context Learners (Dec., 2024)

Track4Gen: Teaching Video Diffusion Models to Track Points Improves Video Generation (Dec., 2024 | CVPR 2025)
Instructional Video Generation (Dec., 2024)
Mimir: Improving Video Diffusion Models for Precise Text Understanding (Dec., 2024)
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling (Dec., 2024)

Identity-Preserving Text-to-Video Generation by Frequency Decomposition (Nov., 2024)

WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model (Nov., 2024)

VideoRepair: Improving Text-to-Video Generation via Misalignment Evaluation and Localized Refinement (Nov., 2024)

Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning (Oct., 2024 | NeurIPS 2024)

Improved Video VAE for Latent Video Diffusion Model (Oct., 2024)
Progressive Autoregressive Video Diffusion Models (Oct., 2024)

Real-Time Video Generation with Pyramid Attention Broadcast (Aug., 2024)

xGen-VideoSyn-1: High-fidelity Text-to-Video Synthesis with Compressed Representations (Aug., 2024)

CogVideoX: Text-to-video generation (Aug., 2024)

FreeLong: Training-Free Long Video Generation with SpectralBlend Temporal Attention (Aug., 2024)
VEnhancer: Generative Space-Time Enhancement for Video Generation (Jul., 2024)

Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models (Jul., 2024)

Video Diffusion Alignment via Reward Gradient (Jul., 2024)

ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning (Jun., 2024)
MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance (Jul., 2024)

Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model (Jun., 2024)

Video-Infinity: Distributed Long Video Generation (Jun., 2024)
MotionBooth: Motion-Aware Customized Text-to-Video Generation (Jun., 2024)
Text-Animator: Controllable Visual Text Video Generation (Jun., 2024)
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation (Jun., 2024)
T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback (May, 2024)
Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control (May, 2024)
Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer (May, 2024)
FIFO-Diffusion: Generating Infinite Videos from Text without Training (May, 2024)

Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models (May, 2024)
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation (May, 2024)

TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models (CVPR 2024)

ID-Animator: Zero-Shot Identity-Preserving Human Video Generation (Apr., 2024)

AnimateZoo: Zero-shot Video Generation of Cross-Species Animation via Subject Alignment (Apr., 2024)

MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators (Apr., 2024)

TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models (CVPR 2024)
VSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis (Mar., 2024)
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text (Mar., 2024)

Intention-driven Ego-to-Exo Video Generation (Mar., 2024)
VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models (Mar., 2024)

Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis (Feb., 2024)
One-Shot Motion Customization of Text-to-Video Diffusion Models (Feb., 2024)
Magic-Me: Identity-Specific Video Customized Diffusion (Feb., 2024)

ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation (Feb., 2024)

Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion (Feb., 2024)
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization (Feb., 2024)

Boximator: Generating Rich and Controllable Motions for Video Synthesis (Feb., 2024)
Lumiere: A Space-Time Diffusion Model for Video Generation (Jan., 2024)
ActAnywhere: Subject-Aware Video Background Generation (Jan., 2024)
WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens (Jan., 2024)

CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects (Jan., 2024)
UniVG: Towards UNIfied-modal Video Generation (Jan., 2024)
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models (Jan., 2024)

360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model (Jan., 2024)
RAVEN: Rethinking Adversarial Video Generation with Efficient Tri-plane Networks (Jan., 2024)
Latte: Latent Diffusion Transformer for Video Generation (Jan., 2024)

MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation (Jan., 2024)
VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM (Jan., 2024)
FlashVideo: A Framework for Swift Inference in Text-to-Video Generation (Dec., 2023)
I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models (Dec., 2023)
A Recipe for Scaling up Text-to-Video Generation with Text-free Videos (Dec., 2023)
PIA: Your Personalized Image Animator via Plug-and-Play Modules in Text-to-Image Models (Dec., 2023)

VideoPoet: A Large Language Model for Zero-Shot Video Generation (Dec., 2023)
InstructVideo: Instructing Video Diffusion Models with Human Feedback (Dec., 2023)

VideoLCM: Video Latent Consistency Model (Dec., 2023)
PEEKABOO: Interactive Video Generation via Masked-Diffusion (Dec., 2023)
FreeInit: Bridging Initialization Gap in Video Diffusion Models (Dec., 2023)

Photorealistic Video Generation with Diffusion Models (Dec., 2023)
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution (Dec., 2023)

DreaMoving: A Human Video Generation Framework based on Diffusion Models (Dec., 2023)

MotionCrafter: One-Shot Motion Customization of Diffusion Models (Dec., 2023)

AnimateZero: Video Diffusion Models are Zero-Shot Image Animators (Dec., 2023)

AVID: Any-Length Video Inpainting with Diffusion Model (Dec., 2023)

MTVG : Multi-text Video Generation with Text-to-Video Models (Dec., 2023)
DreamVideo: Composing Your Dream Videos with Customized Subject and Motion (Dec., 2023)
Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation (Dec., 2023)
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation (CVPR 2024)
GenDeF: Learning Generative Deformation Field for Video Generation (Dec., 2023)

F3-Pruning: A Training-Free and Generalized Pruning Strategy towards Faster and Finer Text-to-Video Synthesis (Dec., 2023)
DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance (Dec., 2023)

LivePhoto: Real Image Animation with Text-guided Motion Control (Dec., 2023)

Fine-grained Controllable Video Generation via Object Appearance and Context (Dec., 2023)
VideoBooth: Diffusion-based Video Generation with Image Prompts (Dec., 2023)

StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter (Dec., 2023)

MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation (Nov., 2023)
ART•V: Auto-Regressive Text-to-Video Generation with Diffusion Models (Nov., 2023)

Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning (Nov., 2023)

VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model (Nov., 2023)
MotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation (Nov., 2023)
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model (Nov., 2023)

FlowZero: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax (Nov., 2023)

Sketch Video Synthesis (Nov., 2023)

Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets (Nov., 2023)

Decouple Content and Motion for Conditional Image-to-Video Generation (Nov., 2023)
FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline (Nov., 2023)

Fine-Grained Open Domain Image Animation with Motion Guidance (Nov., 2023)

GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning (Nov., 2023)

MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer (Nov., 2023)

MoVideo: Motion-Aware Video Generation with Diffusion Models (Nov., 2023)
Make Pixels Dance: High-Dynamic Video Generation (Nov., 2023)
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning (Nov., 2023)
Optimal Noise pursuit for Augmenting Text-to-Video Generation (Nov., 2023)
VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning (Nov., 2023)

SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction (Oct., 2023)

FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling (Oct., 2023)

DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors (Oct., 2023)

LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation (Oct., 2023)

Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation (Sep., 2023)

MotionDirector: Motion Customization of Text-to-Video Diffusion Models (Sep., 2023)

LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models (Sep., 2023)

Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator (Sep., 2023)

Hierarchical Masked 3D Diffusion Model for Video Outpainting (Sep., 2023)
Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation (Sep., 2023)

VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation (Sep., 2023)
MagicAvatar: Multimodal Avatar Generation and Animation (Aug., 2023)

Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models (Aug., 2023)

SimDA: Simple Diffusion Adapter for Efficient Video Generation (Aug., 2023)

ModelScope Text-to-Video Technical Report (Aug., 2023)
Dual-Stream Diffusion Net for Text-to-Video Generation (Aug., 2023)
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (Jul., 2023)

Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation (Jul., 2023)

AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning (Jul., 2023)

DisCo: Disentangled Control for Referring Human Dance Generation in Real World (Jul., 2023)

Learn the Force We Can: Enabling Sparse Motion Control in Multi-Object Video Generation (Jun., 2023)

VideoComposer: Compositional Video Synthesis with Motion Controllability (Jun., 2023)

Probabilistic Adaptation of Text-to-Video Models (Jun., 2023)
Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance (Jun., 2023)

Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising (May, 2023)

Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity (May, 2023)

Any-to-Any Generation via Composable Diffusion (May, 2023)

VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation (May, 2023)
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models (May, 2023)
LaMD: Latent Motion Diffusion for Video Generation (Apr., 2023)
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (CVPR 2023)
Text2Performer: Text-Driven Human Video Generation (Apr., 2023)

Generative Disco: Text-to-Video Generation for Music Visualization (Apr., 2023)
Latent-Shift: Latent Diffusion with Temporal Shift (Apr., 2023)
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion (Apr., 2023)

Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos (Apr., 2023)

Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos (CVPR 2023)

Seer: Language Instructed Video Prediction with Latent Diffusion Models (Mar., 2023)
Text2video-Zero: Text-to-Image Diffusion Models Are Zero-Shot Video Generators (Mar., 2023)

Conditional Image-to-Video Generation with Latent Flow Diffusion Models (CVPR 2023)

Decomposed Diffusion Models for High-Quality Video Generation (CVPR 2023)
Video Probabilistic Diffusion Models in Projected Latent Space (CVPR 2023)

Learning 3D Photography Videos via Self-supervised Diffusion on Single Images (Feb., 2023)
Structure and Content-Guided Video Synthesis With Diffusion Models (Feb., 2023)
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (ICCV 2023)
Mm-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation (CVPR 2023)

Magvit: Masked Generative Video Transformer (Dec., 2022)

VIDM: Video Implicit Diffusion Models (AAAI 2023)

Efficient Video Prediction via Sparsely Conditioned Flow Matching (Nov., 2022)

Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths (Nov., 2022)

SinFusion: Training Diffusion Models on a Single Image or Video (Nov., 2022)
MagicVideo: Efficient Video Generation With Latent Diffusion Models (Nov., 2022)
Imagen Video: High Definition Video Generation With Diffusion Models (Oct., 2022)
Make-A-Video: Text-to-Video Generation without Text-Video Data (ICLR 2023)
Diffusion Models for Video Prediction and Infilling (TMLR 2022)

McVd: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)
Video Diffusion Models (Apr., 2022)
Diffusion Probabilistic Modeling for Video Generation (Mar., 2022)





Efficient Video Generation
SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference (Feb., 2025)
SageAttention2: Efficient Attention with Thorough Outlier Smoothing and Per-thread INT4 Quantization (Feb., 2025)
FlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation (Feb., 2025)

Fast Video Generation with Sliding Tile Attention (Feb, 2025)
Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity (Feb, 2025)
Diffusion Adversarial Post-Training for One-Step Video Generation (Jan, 2025)
From Slow Bidirectional to Fast Causal Video Generators (Dec., 2024)
SnapGen-V: Generating a Five-Second Video within Five Seconds on a Mobile Device (Dec., 2024)
Mobile Video Diffusion (Dec., 2024)
MoViE: Mobile Diffusion for Video Editing (Dec., 2024)
Individual Content and Motion Dynamics Preserved Pruning for Video Diffusion Models (Nov., 2024)
Adaptive Caching for Faster Video Generation with Diffusion Transformers (Nov., 2024)

Fast and Memory-Efficient Video Diffusion Using Streamlined Inference (Nov., 2024)
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration (Oct., 2024)


Controllable Video Generation
ID-Crafter: VLM-Grounded Online RL for Compositional Multi-Subject Video Generation (CVPR, 2026)

Video-As-Prompt: Unified Semantic Control for Video Generation (Nov, 2025)

EgoControl: Controllable Egocentric Video Generation via 3D Full-Body Poses (CVPR 2026)

Hand2World: Autoregressive Egocentric Interaction Generation via Free-Space Hand Gestures (Feb, 2026)
ATI: Any Trajectory Instruction for Controllable Video Generation (Jun., 2025)

TC-Light: Temporally Coherent Generative Rendering for Realistic World Transfer (Jun., 2025)

IllumiCraft: Unified Geometry and Illumination Diffusion for Controllable Video Generation (Jun., 2025)

Frame In-N-Out: Unbounded Controllable Image-to-Video Generation (May, 2025)
VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control (May, 2025 | SIGGRAPH 2025)

FlexiAct: Towards Flexible Action Control in Heterogeneous Scenarios (May, 2025 | SIGGRAPH 2025)

Dynamic Camera Poses and Where to Find Them (Apr., 2025)
GenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography (Apr., 2025)

OmniVDiff: Omni Controllable Video Diffusion for Generation and Understanding (Apr., 2025)

UniAnimate-DiT: Human Image Animation with Large-Scale Video Diffusion Transformer (Apr., 2025)

GenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography (Apr., 2025)
Beyond Static Scenes: Camera-controllable Background Generation for Human Motion (Apr., 2025)

SketchVideo: Sketch-based Video Generation and Editing (Apr., 2025)

Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation (Apr., 2025)
Reangle-A-Video: 4D Video Generation as Video-to-Video Translation (Mar., 2025)

DynamiCtrl: Rethinking the Basic Structure and the Role of Text for High-quality Human Image Animation (Mar., 2025)

HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation (Mar., 2025)

Enabling Versatile Controls for Video Diffusion Models (Mar., 2025)

MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance (Mar., 2025)

MusicInfuser: Making Video Diffusion Listen and Dance (Mar., 2025)

ReCamMaster: Camera-Controlled Generative Rendering from A Single Video (Mar., 2025)

CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models (Mar., 2025)
GEN3C: 3D-Informed World-Consistent Video Generation with Precise Camera Control (Mar., 2025 | CVPR 2025)

C-Drag: Chain-of-Thought Driven Motion Controller for Video Generation (Feb., 2025)

X-Dancer: Expressive Music to Human Dance Video Generation (Feb., 2025)
CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation (Feb., 2025)
RealCam-I2V: Real-World Image-to-Video Generation with Interactive Complex Camera Control (Feb., 2025)
AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance (Feb., 2025)

A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation (Feb., 2025)
VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation (Feb., 2025)
FloVD: Optical Flow Meets Video Diffusion Model for Camera-Controlled Video Synthesis (Feb., 2025)

Light-A-Video: Training-free Video Relighting via Progressive Light Fusion (Feb., 2025)

MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation (Feb., 2025)
MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation (Feb., 2025)
DynVFX: Augmenting Real Videos with Dynamic Content (Feb., 2025)
MotionAgent: Fine-grained Controllable Video Generation via Motion Field Agent (Feb., 2025)
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting (Feb., 2025)
LayerAnimate: Layer-level Control for Animation (Jan., 2025)

Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation (Jan., 2025)

BlobGEN-Vid: Compositional Text-to-Video Generation with Blob Video Representations (Jan., 2025)

On Unifying Video Generation and Camera Pose Estimation (Jan., 2025)
VideoAnydoor: High-fidelity Video Object Insertion with Precise Motion Control (Jan., 2025)
DirectorLLM for Human-Centric Video Generation (Dec., 2024)
Consistent Human Image and Video Generation with Spatially Conditioned Diffusion (Dec., 2024)

Generative Inbetweening through Frame-wise Conditions-Driven Video Generation (Dec., 2024)
InterDyn: Controllable Interactive Dynamics with Video Diffusion Models (Dec., 2024)
OmniDrag: Enabling Motion Control for Omnidirectional Image-to-Video Generation (Dec., 2024)
SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints (Dec., 2024)

3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation (Dec., 2024)

ObjCtrl-2.5D: Training-free Object Control with Camera Poses (Dec., 2024)

Motion Prompting: Controlling Video Generation with Motion Trajectories (Nov., 2024)
Identity-Preserving Text-to-Video Generation by Frequency Decomposition (Nov., 2024)
FlipSketch: Flipping assets Drawings to Text-Guided Sketch Animations (Nov., 2024)

AnimateAnything: Consistent and Controllable Animation for video generation (Nov., 2024)

MVideo: Motion Control for Enhanced Complex Action Video Generation (Nov., 2024)
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning (Nov., 2024 | CVPR 2025)
SG-I2V: Self-Guided Trajectory Control in Image-to-Video Generation (Nov., 2024)

X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention (Nov., 2024)

LumiSculpt: A Consistency Lighting Control Network for Video Generation (Nov., 2024)
FRAMER: INTERACTIVE FRAME INTERPOLATION (Oct., 2024)

CamI2V: Camera-Controlled Image-to-Video Diffusion Model (Oct., 2024)

Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention (Oct., 2024)
Animate Your Motion: Turning Still Images into Dynamic Videos(Mar., 2023|ECCV 2024)
EasyControl: Transfer ControlNet to Video Diffusion for Controllable Generation and Interpolation (Aug., 2024)
ControlNeXt: Powerful and Efficient Control for Image and Video Generation (Aug., 2024)

TrackGo: A Flexible and Efficient Method for Controllable Video Generation (Aug., 2024)
Puppet-Master: Scaling Interactive Video Generation as a Motion Prior for Part-Level Dynamics (Aug., 2024)
Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User's Casual Sketches (Aug., 2024)
Expressive Whole-Body 3D Gaussian Avatar (Aug., 2024)
Tora: Trajectory-oriented Diffusion Transformer for Video Generation (Jul., 2024 | CVPR 2025)

HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation (Jul., 2024)

Cinemo: Consistent and Controllable Image Animation with Motion Diffusion Models (Jul., 2024)

VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control (Jul., 2024)
Still-Moving: Customized Video Generation without Customized Video Data (Jul., 2024)
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control (Jul., 2024)

Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model (Jun., 2024 | NeurIPS 2024)
Image Conductor: Precision Control for Interactive Video Synthesis (Jun., 2024)

MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance (Jun., 2024)
FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models (Jun., 2024)

Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance (Mar., 2024)

TrailBlazer: Trajectory Control for Diffusion-Based Video Generation (Jan., 2024)

Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation (Jan., 2024)
Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions (Jan., 2024)
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation (Dec., 2023)

Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation (Nov., 2023)

SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models (Nov., 2023)
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models (May, 2023)

Motion-Conditioned Diffusion Model for Controllable Video Synthesis (Apr., 2023)
ControlVideo: Training-free Controllable Text-to-Video Generation (May, 2023)

DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory (Aug., 2023)
DragAnything: Motion Control for Anything using Entity Representation (ECCV, 2024)

CameraCtrl: Enabling Camera Control for Video Diffusion Models (Apr., 2024)

Training-free Camera Control for Video Generation (Jun., 2024)
Customizing Motion in Text-to-Video Diffusion Models (Dec., 2023)
MotionClone: Training-Free Motion Cloning for Controllable Video Generation (Jun., 2024)

Character Customization
FlexiAct: Towards Flexible Action Control in Heterogeneous Scenarios (May, 2025 | SIGGRAPH 2025)
HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation (May., 2025)

VideoMage: Multi-Subject and Motion Customization of Text-to-Video Diffusion Models (Mar., 2025)
MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization (Mar., 2025)

Concat-ID: Towards Universal Identity-Preserving Video Synthesis (Mar., 2025)

CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance (Mar., 2025)
FantasyID: Face Knowledge Enhanced ID-Preserving Video Generation (Feb., 2025)
Dynamic Concepts Personalization from Single Videos (Feb., 2025)
Phantom: Subject-consistent video generation via cross-modal alignment (Feb., 2025)

Movie Weaver: Tuning-Free Multi-Concept Video Personalization with Anchored Prompts (Feb., 2025)
Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance (Feb., 2025)
Multi-subject Open-set Personalization in Video Generation (Jan., 2025)
Magic Mirror: ID-Preserved Video Generation in Video Diffusion Transformers (Jan., 2025)

ConceptMaster: Multi-Concept Video Customization on Diffusion Transformer Models Without Test-Time Tuning (Jan., 2025)
VideoMaker: Zero-shot Customized Video Generation with the Inherent Force of Video Diffusion Models (Dec., 2024)

PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation (Nov., 2024)
DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control (Oct., 2024)
CustomCrafter: Customized Video Generation with Preserving Motion and Concept Composition Abilities (Aug., 2024)

Motion Customization
TrajectoryMover: Generative Movement of Object Trajectories in Videos (Mar., 2026)

Frame In-N-Out: Unbounded Controllable Image-to-Video Generation (May, 2025)
MotionPro: A Precise Motion Controller for Image-to-Video Generation (May, 2025 | CVPR 2025)

LMP: Leveraging Motion Prior in Zero-Shot Video Generation with Diffusion Transformer (May, 2025)
FlexiAct: Towards Flexible Action Control in Heterogeneous Scenarios (May, 2025 | SIGGRAPH 2025)
Training-free Guidance in Text-to-Video Generation via Multimodal Planning and Structured Noise Initialization (Apr., 2025)

Separate Motion from Appearance: Customizing Motion via Customizing Text-to-Video Diffusion Models (Feb., 2025)
Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise (Jan., 2025)

Training-Free Motion-Guided Video Generation with Enhanced Temporal Consistency Using Motion Consistency Loss (Jan., 2025)
Free-Form Motion Control: A Synthetic Video Generation Dataset with Controllable Camera and Object Motions (Jan., 2025)
CustomTTT: Motion and Appearance Customized Video Generation via Test-Time Training (Dec., 2024)
MotionShop: Zero-Shot Motion Transfer in Video Diffusion Models with Mixture of Score Guidance (Dec., 2024)

Video Motion Transfer with Diffusion Transformers (Dec., 2024)

Latent-Reframe: Enabling Camera Control for Video Diffusion Model without Training (Dec., 2024)
Motion Modes: What Could Happen Next? (Dec., 2024)
MoTrans: Customized Motion Transfer with Text-driven Video (Dec., 2024)
AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers (Dec., 2024)
Trajectory Attention For Fine-grained Video Motion Control (Dec., 2024)

ViewExtrapolator: Novel View Extrapolation with Video Diffusion Priors (Nov., 2024)

I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength (Nov., 2024)
MotionDirector: Motion Customization of Text-to-Video Diffusion Models (Sep., 2023 | ECCV 2024)
LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation (Oct., 2023 | CVPR 2024)
Vmc: Video motion customization using temporal attention adaption for text-to-video diffusion models (Dec., 2023 | CVPR 2024)

DreamVideo: Composing Your Dream Videos with Customized Subject and Motion (Dec., 2023 | CVPR 2024)

MotionCtrl: A Unified and Flexible Motion Controller for Video Generation (Dec., 2023 | SIGGRAPH 2024)
Customizing Motion in Text-to-Video Diffusion Models (Dec., 2023)
Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion (Feb., 2024)

Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models (Feb., 2024)
DreamMotion: Space-Time Self-Similar Score Distillation for Zero-Shot Video Editing (Mar., 2024 | ECCV 2024)
DragAnything: Motion Control for Anything using Entity Representation (Mar., 2024 | ECCV 2024)
Spectral Motion Alignment for Video Motion Transfer using Diffusion Models (Mar., 2024)

Motion Inversion for Video Customization (Mar., 2024)

Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing (Mar., 2024)
Video Diffusion Models are Training-free Motion Interpreter and Controller (May., 2024)
Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control (May., 2024)

MotionClone: Training-Free Motion Cloning for Controllable Video Generation (Jun., 2024)

FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models (Jun., 2024)
Zero-Shot Controllable Image-to-Video Animation via Motion Decomposition (Jul., 2024 | ACM MM 2024)
Tora: Trajectory-oriented Diffusion Transformer for Video Generation (Jul., 2024)
Reenact Anything: Semantic Video Motion Transfer Using Motion-Textual Inversion (Aug., 2024)
Long Video / Film Generation
A²RD: Agentic Autoregressive Diffusion for Long Video Consistency (May., 2026)
Stable Video Infinity: Infinite-Length Video Generation with Error Recycling (Oct., 2025)

AnimeShooter: A Multi-Shot Animation Dataset for Reference-Guided Video Generation (Jun., 2025)

VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control (May, 2025 | SIGGRAPH 2025)
One-Minute Video Generation with Test-Time Training (Apr., 2025)

Mask²DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation (Mar., 2025 | CVPR 2025)

Long-Context Autoregressive Video Modeling with Next-Frame Prediction (Mar., 2025)

MovieAgent: Automated Movie Generation via Multi-Agent CoT Planning (Mar., 2025)

Long Context Tuning for Video Generation (Mar., 2025)
RIFLEx: A Free Lunch for Length Extrapolation in Video Diffusion Transformers (Feb., 2025)
VideoRAG: Retrieval-Augmented Generation with Extreme Long-Context Videos (Feb., 2025)

Ouroboros-Diffusion: Exploring Consistent Content Generation in Tuning-free Long Video Diffusion (Jan., 2025)
VideoAuteur: Towards Long Narrative Video Generation (Jan., 2025)

LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity (Dec., 2024)
Owl-1: Omni World Model for Consistent Long Video Generation (Dec., 2024)

Video Storyboarding: Multi-Shot Character Consistency for Text-to-Video Generation (Dec., 2024)
Mind the Time: Temporally-Controlled Multi-Event Video Generation (Dec., 2024)

GenMAC: Compositional Text-to-Video Generation with Multi-Agent Collaboration (Dec., 2024)
Long Video Diffusion Generation with Segmented Cross-Attention and Content-Rich Video Data Curation (Dec., 2024)
VideoGen-of-Thought: A Collaborative Framework for Multi-Shot Video Generation (Dec., 2024)
MotionCharacter: Identity-Preserving and Motion Controllable Human Video Generation (Nov., 2024)
Identity-Preserving Text-to-Video Generation by Frequency Decomposition (Nov., 2024)
MovieBench: A Hierarchical Movie Level Dataset for Long Video Generation (CVPR 2025)

MotionPrompt: Optical-Flow Guided Prompt Optimization for Coherent Video Generation (Nov., 2024)

DreamRunner: Fine-Grained Storytelling Video Generation with Retrieval-Augmented Motion Adaptation (Nov., 2024)

StoryMaker: Towards consistent characters in text-to-image generation (Nov., 2024)

Storynizor: Consistent Story Generation via Inter-Frame Synchronized and Shuffled ID Injection (Nov., 2024)
ACDC: Autoregressive Coherent Multimodal Generation using Diffusion Correction (Nov., 2024)
Story-Adapter: A Training-free Iterative Framework for Long Story Visualization (Nov., 2024)

In-Context LoRA for Diffusion Transformers (Aug., 2024)

SEED-Story: Multimodal Long Story Generation with Large Language Model (Jul., 2024)

StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration (Nov., 2024)
ARLON: Boosting Diffusion Transformers With Autoregressive Models for Long Video Generation (Oct., 2024)
Unbounded: A Generative Infinite Game of Character Life Simulation (Oct., 2024)
Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach (Oct., 2024)

Loong: Generating Minute-level Long Videos with Autoregressive Language Models (Oct., 2024)
DreamCinema: Cinematic Transfer with Free Camera and 3D Character (Oct., 2024)
CinePreGen: Camera Controllable Video Previsualization via Engine-powered Diffusion (Aug., 2024)
DreamCinema: Cinematic Transfer with Free Camera and 3D Character (Aug., 2024)

SkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama (Aug., 2024)

Anim-Director: A Large Multimodal Model Powered Agent for Controllable Animation Video Generation (Aug., 2024)

Kubrick: Multimodal Agent Collaborations for Synthetic Video Generation (Aug., 2024)
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework (Jul, 2024)
MovieDreamer: Hierarchical Generation for Coherent Long Visual Sequence (Jul, 2024)

Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion (Jul., 2024)
AutoAD-Zero: A Training-Free Framework for Zero-Shot Audio Description (Jul, 2024)

AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production (Jul, 2024)
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation (Jul, 2024)

AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation (Jul, 2024)

DreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion (Jul, 2024)
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning (Jul, 2024)

MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)

NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation (Mar., 2023)
Flexible Diffusion Modeling of Long Videos (May, 2022)


Video Generation with 3D/Physical Prior
Over++: Generative Video Compositing for Layer Interaction Effects (Dec, 2025)

Force Prompting: Video Generation Models Can Learn and Generalize Physics-based Control Signals (May, 2025)

ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction](https://arxiv.org/abs/2504.21855) (Apr, 2025)
SyncVP: Joint Diffusion for Synchronous Multi-Modal Video Prediction (CVPR 2025)

DiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models (Feb, 2025)
Generative Physical AI in Vision: A Survey (Jan, 2025)

Do generative video models learn physical principles from watching videos? (Jan, 2025)
Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control (Jan, 2025)

Motion Dreamer: Realizing Physically Coherent Video Generation through Scene-Aware Motion Reasoning (Nov, 2024)
PhyT2V: LLM-Guided Iterative Self-Refinement for Physics-Grounded Text-to-Video Generation (Nov, 2024)

PhysMotion: Physics-Grounded Dynamics From a Single Image (Nov, 2024)
AutoVFX: Physically Realistic Video Editing from Natural Language Instructions (Nov, 2024)

How Far is Video Generation from World Model: A Physical Law Perspective (Oct, 2024)

Tex4D: Zero-shot 4D Scene Texturing with Video Diffusion Models (Oct, 2024)

PhyGenBench: Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation (Oct, 2024)

PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation (Oct, 2024)

StereoCrafter: Diffusion-based Generation of Long and High-fidelity Stereoscopic 3D from Monocular Videos (Oct, 2024)
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis (Sep, 2024)

Compositional 3D-aware Video Generation with LLM Director (Aug, 2024)
IDOL: Unified Dual-Modal Latent Diffusion for Human-Centric Joint Video-Depth Generation (Jul, 2024)

PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation (ECCV 2024)

Video Editing
Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance (Mar., 2026)

NOVA: Sparse Control, Dense Synthesis for Pair-Free Video Editing (Mar., 2026)

VideoCoF: Unified Video Editing with Temporal Reasoner (Dec., 2025 | CVPR 2026)

MotionV2V: Editing Motion in a Video (Nov., 2025)

Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset (Oct., 2025)

EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning (Sep., 2025)

OmniInsert: Mask-Free Video Insertion of Any Reference via Diffusion Transformer Models (Sep., 2025)

MiniMax-Remover: Taming Bad Noise Helps Video Object Removal (May, 2025)

LoRA-Edit: Controllable First-Frame-Guided Video Editing via Mask-Aware LoRA Fine-Tuning (Jun, 2025)

UNIC: Unified In-Context Video Editing (Jun, 2025)
VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control (May, 2025 | SIGGRAPH 2025)
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation (Apr., 2025)

MTV-Inpaint: Multi-Task Long Video Inpainting (Mar., 2025)
Señorita-2M : A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists (Mar., 2025)

VideoGrain: Modulating Space-Time Attention for Multi-grained Video Editing (Feb., 2025 | ICLR 2025)

Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation (Jan., 2025)
Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning (Jan., 2025)
MIVE: New Design and Benchmark for Multi-Instance Video Editing (Dec., 2024)
VividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping (Dec., 2024)

MotionFlow: Attention-Driven Motion Transfer in Video Diffusion Models (Dec., 2024)
DIVE: Taming DINO for Subject-Driven Video Editing (Dec., 2024)
AniGS: Animatable Gaussian Avatar from a Single Image with Inconsistent Gaussian Reconstruction (Dec., 2024)

StableV2V: Stablizing Shape Consistency in Video-to-Video Editing (Nov, 2024)

Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection (May, 2024)
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models (May, 2024)
Looking Backward: Streaming Video-to-Video Translation with Feature Banks (May, 2024)

ReVideo: Remake a Video with Motion and Content Control (May, 2024)

Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices (May, 2024)

ViViD: Video Virtual Try-on using Diffusion Models (May, 2024)

Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing (May, 2024)
GenVideo: One-shot target-image and shape aware video editing using T2I diffusion models (Apr., 2024)
EVA: Zero-shot Accurate Attributes and Multi-Object Video Editing (Mar., 2024)

Spectral Motion Alignment for Video Motion Transfer using Diffusion Models (Mar., 2024)
AnyV2V: A Tuning-Free Framework For Any Video-to-Video Editing Tasks (Mar., 2024)

CoCoCo: Improving Text-Guided Video Inpainting for Better Consistency, Controllability and Compatibility (Mar., 2024)

DreamMotion: Space-Time Self-Similarity Score Distillation for Zero-Shot Video Editing (Mar., 2024)
Video Editing via Factorized Diffusion Distillation (Mar., 2024)
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing (Mar., 2024)
UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing (Feb., 2024)

Object-Centric Diffusion for Efficient Video Editing (Jan., 2024)
VASE: Object-Centric Shape and Appearance Manipulation of Real Videos (Jan., 2024)

FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis (Dec., 2023)

Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis (Dec., 2023)
RealCraft: Attention Control as A Solution for Zero-shot Long Video Editing (Dec., 2023)
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers (Dec., 2023)
VidToMe: Video Token Merging for Zero-Shot Video Editing (Dec., 2023)

A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing (Dec., 2023)

Neutral Editing Framework for Diffusion-based Video Editing (Dec., 2023)
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing (Dec., 2023)
RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models (Dec., 2023)

SAVE: Protagonist Diversification with Structure Agnostic Video Editing (Dec., 2023)
MagicStick: Controllable Video Editing via Control Handle Transformations (Dec., 2023)

VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence (CVPR 2024)

DragVideo: Interactive Drag-style Video Editing (Dec., 2023)

Drag-A-Video: Non-rigid Video Editing with Point-based Interaction (Dec., 2023)
BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models (Dec., 2023)
VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models (CVPR 2024)
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing (ICLR 2024)

MotionEditor: Editing Video Motion via Content-Aware Diffusion (Nov., 2023)

Motion-Conditioned Image Animation for Video Editing (Nov., 2023)
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer (CVPR 2024)
Cut-and-Paste: Subject-Driven Video Editing with Attention Control (Nov., 2023)
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation (Nov., 2023)
Fuse Your Latents: Video Editing with Multi-source Latent Diffusion Models (Oct., 2023)
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing (Oct., 2023)
Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models (ICLR 2024)

CCEdit: Creative and Controllable Video Editing via Diffusion Models (Sep., 2023)
MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation (Sep., 2023)
MagicEdit: High-Fidelity and Temporally Coherent Video Editing (Aug., 2023)

StableVideo: Text-driven Consistency-aware Diffusion Video Editing (ICCV 2023)

CoDeF: Content Deformation Fields for Temporally Consistent Video Processing (CVPR 2024)

TokenFlow: Consistent Diffusion Features for Consistent Video Editing (ICLR 2024)

INVE: Interactive Neural Video Editing (Jul., 2023)
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing (Jun., 2023)
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation (SIGGRAPH Asia 2023)

ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing (May, 2023)

Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts (May, 2023)

Soundini: Sound-Guided Diffusion for Natural Video Editing (Apr., 2023)

Zero-Shot Video Editing Using Off-the-Shelf Image Diffusion Models (Mar., 2023)

Edit-A-Video: Single Video Editing with Object-Aware Consistency (Mar., 2023)
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (Mar., 2023)

Pix2video: Video Editing Using Image Diffusion (Mar., 2023)
Video-P2P: Video Editing with Cross-attention Control (Mar., 2023)

Dreamix: Video Diffusion Models Are General Video Editors (Feb., 2023)
Shape-Aware Text-Driven Layered Video Editing (Jan., 2023)
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model (Jan., 2023)


Human or Subject Motion
MTVCrafter: 4D Motion Tokenization for Open-World Human Image Animation (May., 2025)

AnyTop: Character Animation Diffusion with Any Topology (Feb., 2025)

HumanDiT: Pose-Guided Diffusion Transformer for Long-form Human Motion Video Generation (Feb., 2025)
VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models (Feb., 2025)
OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models (Feb., 2025)
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation (Nov., 2024)

KMM: Key Frame Mask Mamba for Extended Motion Generation (Nov., 2024)

DanceFusion: A Spatio-Temporal Skeleton Diffusion Transformer for Audio-Driven Dance Motion Reconstruction (Nov., 2024)
Enhancing Motion in Text-to-Video Generation with Decomposed Encoding and Conditioning (Nov., 2024)

A Comprehensive Survey on Human Video Generation: Challenges, Methods, and Insights (Jul., 2024)
OccFusion: Rendering Occluded Humans with Generative Diffusion Priors (Jul., 2024)
EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions (Jul., 2024)

Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model (CVPR 2023)

InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions (Apr., 2023)

ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model (Apr., 2023)

Human Motion Diffusion as a Generative Prior (Mar., 2023)

Can We Use Diffusion Probabilistic Models for 3d Motion Prediction? (Feb., 2023)

Single Motion Diffusion (Feb., 2023)

HumanMAC: Masked Motion Completion for Human Motion Prediction (Feb., 2023)

DiffMotion: Speech-Driven Gesture Synthesis Using Denoising Diffusion Model (Jan., 2023)
Modiff: Action-Conditioned 3d Motion Generation With Denoising Diffusion Probabilistic Models (Jan., 2023)
Unifying Human Motion Synthesis and Style Transfer With Denoising Diffusion Probabilistic Models (GRAPP 2023)

Executing Your Commands via Motion Diffusion in Latent Space (CVPR 2023)

Pretrained Diffusion Models for Unified Human Motion Synthesis (Dec., 2022)
PhysDiff: Physics-Guided Human Motion Diffusion Model (Dec., 2022)
BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction (Dec., 2022)

Diffusion Motion: Generate Text-Guided 3d Human Motion by Diffusion Model (ICASSP 2023)
Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction (Oct., 2022)
Human Motion Diffusion Model (ICLR 2023)

FLAME: Free-form Language-based Motion Synthesis & Editing (AAAI 2023)

MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model (Aug., 2022)

Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion (CVPR 2022)


Video Enhancement and Restoration
Enhance-A-Video: Better Generated Video for Free (Feb., 2025)

SVFR: A Unified Framework for Generalized Video Face Restoration (Jan., 2025)
Disentangled Motion Modeling for Video Frame Interpolation (Jun, 2024)

DiffIR2VR-Zero: Zero-Shot Video Restoration with Diffusion-based Image Restoration Models (Jul., 2024)
LDMVFI: Video Frame Interpolation with Latent Diffusion Models (Mar., 2023)
CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming (Nov., 2022)
Audio Synthesis for Video
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation (Feb., 2025)
UniForm: A Unified Diffusion Transformer for Audio-Video Generation (Feb., 2025)
AGAV-Rater: Enhancing LMM for AI-Generated Audio-Visual Quality Assessment (Jan., 2025)
XMusic: Towards a Generalized and Controllable Symbolic Music Generation Framework (Jan., 2025)
Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis (Dec., 2024)

Stable-V2A: Synthesis of Synchronized Audio Effects with Temporal and Semantic Controls (Dec., 2024)

AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation (Dec., 2024)

VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation (Nov., 2024)
YingSound: Video-Guided Sound Effects Generation with Multi-modal Chain-of-Thought Controls (Nov., 2024)
Video-Guided Foley Sound Generation with Multimodal Controls (Nov., 2024)
MuVi: Video-to-Music Generation with Semantic Alignment and Rhythmic Synchronization (Oct., 2024)
Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation (Sep., 2023)

VMAs: Video-to-Music Generation via Semantic Alignment in Web Music Videos (Oct., 2024)
STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment (Oct., 2024)

Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis (Sep., 2024)
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming (Jul., 2024)

Speech To Speech: an effort for an open-sourced and modular GPT4-o (Aug., 2024)

Video-Foley: Two-Stage Video-To-Sound Generation via Temporal Event Condition For Foley Sound (Aug., 2024)

Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity (Jul., 2024)
Video-to-Audio Generation with Hidden Alignment (Jul., 2024)

Read, Watch and Scream! Sound Generation from Text and Video (Jul., 2024)

FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds (July, 2024)
Network Bending of Diffusion Models for Audio-Visual Generation (CVPR, 2024)

Talking Head Generation
TalkingMachines: Real-Time Audio-Driven FaceTime-Style Video via Autoregressive Diffusion Models (Jun., 2025)

IM-Portrait: Learning 3D-aware Video Diffusion for Photorealistic Talking Heads from Monocular Videos (May, 2025)
KeySync: A Robust Approach for Leakage-free Lip Synchronization in High Resolution (May, 2025)

OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication (Apr., 2025)
MoCha: Towards Movie-Grade Talking Character Synthesis (Apr., 2025)
SayAnything: Audio-Driven Lip Synchronization with Conditional Video Diffusion (Feb., 2025)
VQTalker: Towards Multilingual Talking Avatars through Facial Motion Tokenization (Dec., 2024)
IF-MDM: Implicit Face Motion Diffusion Model for High-Fidelity Realtime Talking Head Generation (Dec., 2024)
INFP: Audio-Driven Interactive Head Generation in Dyadic Conversations (Dec., 2024)
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation (Dec., 2024)

SINGER: Vivid Audio-driven Singing Video Generation with Multi-scale Spectral Diffusion Model (Dec., 2024)
Synergizing Motion and Appearance: Multi-Scale Compensatory Codebooks for Talking Head Video Generation (Nov., 2024)

Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks (Nov., 2024)
FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait (Nov., 2024)
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion (Nov., 2024)
LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis (Nov., 2024)
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency (Nov., 2024)
PersonaTalk: Bring Attention to Your Persona in Visual Dubbing (Oct., 2024)
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion (Oct., 2024)

GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents (Oct., 2024)
From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations (Oct., 2024)
Takin-ADA: Emotion Controllable Audio-Driven Animation with Canonical and Landmark Loss Optimization (Oct., 2024)
DAWN: Dynamic Frame Avatar with Non-autoregressive Diffusion Framework for Talking Head Video Generation (Oct., 2024)

MimicTalk: Mimicking a personalized and expressive 3D talking face in few minutes (Oct., 2024)

Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation (Oct., 2024)

Listen, Denoise, Action! Audio-Driven Motion Synthesis With Diffusion Models (Nov. 2022)
TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation (Oct., 2024)
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation (Jun., 2024)



Reinforcement Learning for Video Generation
Scaling Image and Video Generation via Test-Time Evolutionary Search (Jun., 2025)

DenseDPO: Fine-Grained Temporal Preference Optimization for Video Diffusion Models (Jun., 2025)
LiFT: Leveraging Human Feedback for Text-to-Video Model Alignment (Dec., 2024)

Improving Dynamic Object Interactions in Text-to-Video Generation with AI Feedback (Nov., 2024)
VIDEOSCORE: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation (July, 2024)

Policy Learning
Object-Centric Image to Video Generation with Language Guidance (Feb, 2025)

Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations (Dec, 2024)
Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning (Dec, 2024)
Stag-1: Towards Realistic 4D Driving Simulation with Video Generation Model (Dec, 2024)

RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (Dec, 2024)
EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation (Nov, 2024)

GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal Conditioned Policy (July, 2024)

Any-point Trajectory Modeling for Policy Learning (July, 2024)

This&That: Language-Gesture Controlled Video Generation for Robot Planning (Jun, 2024)

Dreamitate: Real-World Visuomotor Policy Learning via Video Generation (Jun, 2024)

Virtual Try-On
1-2-1: Renaissance of Single-Network Paradigm for Virtual Try-On (Jan., 2025)

Dynamic Try-On: Taming Video Virtual Try-on with Dynamic Attention Mechanism (Dec., 2024)
Fashion-VDM: Video Diffusion Model for Virtual Try-On (Nov., 2024)
3D
Monocular Normal Estimation via Shading Sequence Estimation (Feb., 2026)
WorldExplorer: Towards Generating Fully Navigable 3D Scenes (Jun., 2025)
Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation (Jun., 2025)

Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models (Mar., 2025 | CVPR 2025)
Wonderland: Navigating 3D Scenes from a Single Image (Dec., 2024)
GPT-4V(ision) is a Human-Aligned Evaluator for Text-to-3D Generation (Jan., 2024)
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion (Oct., 2024)

L3DG: Latent 3D Gaussian Diffusion (Oct., 2024)
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model (Oct., 2024)

Hi3D: Pursuing High-Resolution Image-to-3D Generation with Video Diffusion Models (Oct., 2024)

ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model (Aug., 2024)
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency (Jul., 2024)
Shape of Motion: 4D Reconstruction from a Single Video (Jul., 2024)

WonderWorld: Interactive 3D Scene Generation from a Single Image (Jun., 2024)
WonderJourney: Going from Anywhere to Everywhere (CVPR 2024)

MultiDiff: Consistent Novel View Synthesis from a Single Image (CVPR, 2024)
ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (CVPR, 2024)

Vivid-ZOO: Multi-View Video Generation with Diffusion Model (Jun, 2024)

Director3D: Real-world Camera Trajectory and 3D Scene Generation from Text (June, 2024)

YouDream: Generating Anatomically Controllable Consistent Text-to-3D Animals (June, 2024)

Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields (May, 2023)
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture (May, 2023)
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models (CVPR 2023)
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction (Apr., 2023)
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions (Mar., 2023)

Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models (Mar., 2023)

DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models (Feb., 2023)

NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion (Feb., 2023)
DiffRF: Rendering-guided 3D Radiance Field Diffusion (CVPR 2023)
4D
Diff4Splat: Controllable 4D Scene Generation with Latent Dynamic Reconstruction Models (November, 2025)

Diffuman4D: 4D Consistent Human View Synthesis from Sparse-View Videos with Spatio-Temporal Diffusion Models (July, 2025)

Diffuman4D: 4D Consistent Human View Synthesis from Sparse-View Videos with Spatio-Temporal Diffusion Models (July, 2025)
Taming Video Diffusion Models for Panoramic 4D Scene Generation (May, 2025)

In-2-4D: Inbetweening from Two Single-View Images to 4D Generation (Apr, 2025)

Vivid4D: Improving 4D Reconstruction from Monocular Video by Video Inpainting (Apr., 2025)
AvatarArtist: Open-Domain 4D Avatarization (Apr., 2025)

Not All Frame Features Are Equal: Video-to-4D Generation via Decoupling Dynamic-Static Features (Feb., 2025)

DreamDrive: Generative 4D Scene Modeling from Street View Images (Jan., 2025)
Stereo4D Learning How Things Move in 3D from Internet Stereo Videos (Dec., 2024)
4Real-Video: Learning Generalizable Photo-Realistic 4D Video Diffusion (Dec., 2024)
PaintScene4D: Consistent 4D Scene Generation from Text Prompts (Dec., 2024)
CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models (Nov., 2024)
DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion (Nov., 2024)

Game Generation
- Playable Game Generation (Nov., 2024)
AI Safety
Rendering with Virtual Engine
UnrealZoo: Enriching Photo-realistic Virtual Worlds for Embodied AI (Jan., 2025)

Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation (CVPR 2024)
Scene Co-pilot: Procedural Text to Video Generation with Human in the Loop (Dec., 2024)
Open-World Model
Inference-time Physics Alignment of Video Generative Models with Latent World Models (Jan., 2026)

Vid2World: Crafting Video Diffusion Models to Interactive World Models (May., 2025)
WORLDMEM: Long-term Consistent World Simulation with Memory (Apr., 2025)

MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft (Apr., 2025)

Aether: Geometric-Aware Unified World Modeling (Mar., 2025)

Pre-Trained Video Generative Models as World Simulators (Feb., 2025)
VideoWorld: Exploring Knowledge Learning from Unlabeled Videos (Jan., 2025)

GameFactory: Creating New Games with Generative Interactive Videos (Jan., 2025)

Vid2Sim: Realistic and Interactive Simulation from Video for Urban Navigation (Jan., 2025)
GenEx: Generating an Explorable World (Dec., 2024)
The Matrix: Infinite-Horizon World Generation with Real-Time Moving Control (Dec., 2024)
Navigation World Models (Dec., 2024)
Genie 2: A large-scale foundation world model (Dec., 2024)
Understanding World or Predicting Future? A Comprehensive Survey of World Models (Nov., 2024)
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents (Nov., 2024)

Oasis: A Universe in a Transformer (Nov., 2024)

Digital Life Project: Autonomous 3D Characters with Social Intelligence (CVPR 2024)

3D-VLA: A 3D Vision-Language-Action Generative World Model (ICML 2024)

Video Understanding
UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics (Dec., 2024)
Divot: Diffusion Powers Video Tokenizer for Comprehension and Generation (Nov., 2024)

VLM-Grounder: A VLM Agent for Zero-Shot 3D Visual Grounding (Oct., 2024)

Exploring Diffusion Models for Unsupervised Video Anomaly Detection (Apr., 2023)
PDPP:Projected Diffusion for Procedure Planning in Instructional Videos (CVPR 2023)

DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion (Mar., 2023)

Diffusion Action Segmentation (ICCV 2023)

DiffusionRet: Generative Text-Video Retrieval with Diffusion Model (ICCV 2023)

Refined Semantic Enhancement Towards Frequency Diffusion for Video Captioning (Nov., 2022)

A Generalist Framework for Panoptic Segmentation of Images and Videos (Oct., 2022)

Healthcare and Biology
FEAT: Full-Dimensional Efficient Attention Transformer for Medical Video Generation (Jun., 2025)

Medical Video Generation for Disease Progression Simulation (Nov., 2024)
Artificial Intelligence for Biomedical Video Generation (Nov., 2024)
Exploring Variational Autoencoders for Medical Image Generation: A Comprehensive Study (Nov., 2024)
MedSora: Optical Flow Representation Alignment Mamba Diffusion Model for Medical Video Generation (Nov., 2024)
Annealed Score-Based Diffusion Model for Mr Motion Artifact Reduction (Jan., 2023)
Feature-Conditioned Cascaded Video Diffusion Models for Precise Echocardiogram Synthesis (Mar., 2023)
Neural Cell Video Synthesis via Optical-Flow Diffusion (Dec., 2022)
Other Applications
History-Guided Video Diffusion (Feb., 2025)

VidSketch: Hand-drawn Sketch-Driven Video Generation with Diffusion Control (Feb., 2025)
VanGogh: A Unified Multimodal Diffusion-based Framework for Video Colorization (Jan., 2025)

PhysAnimator: Physics-Guided Generative Cartoon Animation (Feb., 2025)
Code-rendered Video Generation
Code2Video: A Code-centric Paradigm for Educational Video Generation (Oct., 2025)

Paper2Video: Automatic Video Generation from Scientific Papers (Oct., 2025)

- AgentMarket - B2A marketplace for AI agents. 189 APIs, 28M+ data.